
The basic know-how for a data role is the ability to perform an ETL process. It does not matter which tool you are using be it spark or excel. So, how about we journey on a simple ETL process using spark and scala.
Extract
I will be demonstrating this using the Boston housing dataset. Spark supports different file formats the most common to spark is Parquet. However, we are using a CSV file.
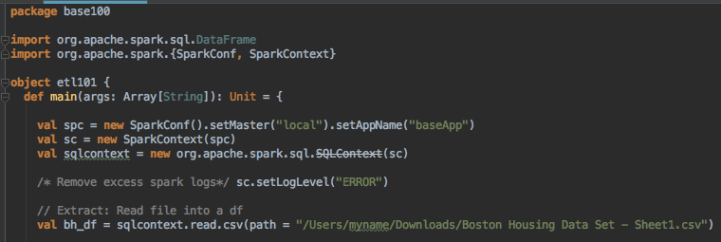
This is assuming you have some experience with Spark, please refer to A Newbie’s Guide to Big Data for for details.
Before transformation begins, it helps to know what the data looks like. An example will be using pivot in excel, displaying the first three rows of the new data frame we can see that the columns are not properly named.
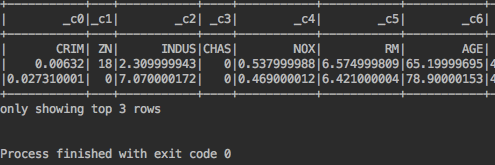
Transform
Three steps are taken to transform the data. We use .first() to store the first row, .alias() to rename the columns and .filter() to take out the first row.
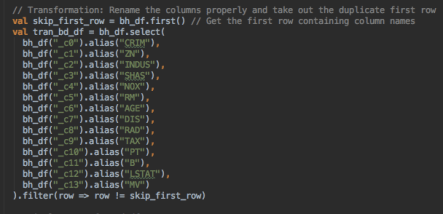

Load
Once the transformation is complete we can load the transformed data for further analysis.
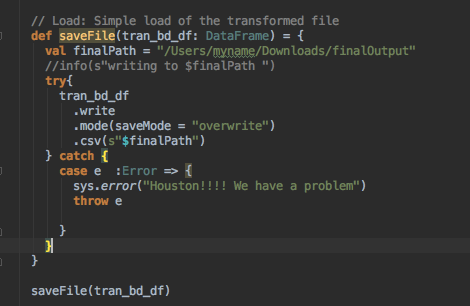
This really is to give you a simple introduction to ETL. So, the next time you asked about it, just know its not all that complex.
After loading the data what next? Is it large? Want to perform data partition?
PS: Refer to my GitHub for the complete code. Let me know what you think.
